Corpus di Italiano Scritto contemporaneo ricco di circa 100 milioni di parole. Elaborato e prodotto dal Centro Interfacoltà di Linguistica Teorica e Applicata (CILTA) "Luigi Heilmann" dell'Universita' di Bologna, prevede una licenza per l'accesso alla versione completa.
Il corpus di riferimento è costituito da testi tratti da quotidiani del periodo 1992 - 1994 (La Repubblica, La Stampa, Il Corriere della Sera), periodici e libri, considerando anche i libri letti per motivi scolastici o professionali. Consta di 3.150.075 ricorrenze lessicali. Al progetto partecipano i seguenti soggetti: Scuola Normale Superiore (Pisa), Istituto di Scienze e Tecnologie della Cognizione del CNR (Roma), Università di Salerno, Istituto di Linguistica Computazionale, Unità Staccata di Genova del CNR, Università de L'Aquila.
Corpus molto ampio (circa 380mila parole) del lessico del quotidiano la Repubblica. Nel progetto, curato dall'Università di Bologna, il corpus è stato lemmatizzato, taggato e categorizzato per genere e topic; gli articoli nel corpus sono strutturati nelle seguenti parti:titolo, sottotitolo, sommario, testo.
il corpus LIP, ospitato sul sito della Banca Dati dell'Italiano Parlato (BaDIP), è la raccolta di testi dell'italiano parlato più importante e più utilizzata nella ricerca linguistica. Costituito nel 1990-1992 da un gruppo di linguisti diretto da Tullio De Mauro, serví per costruire il primo lessico di frequenza dell' italiano parlato. I suoi 469 testi, contenenti complessivamente ca. 490.000 parole, furono raccolti in quattro città (Milano, Firenze, Roma e Napoli) e provengono da cinque macroclassi e numerose sottoclassi di discorso.
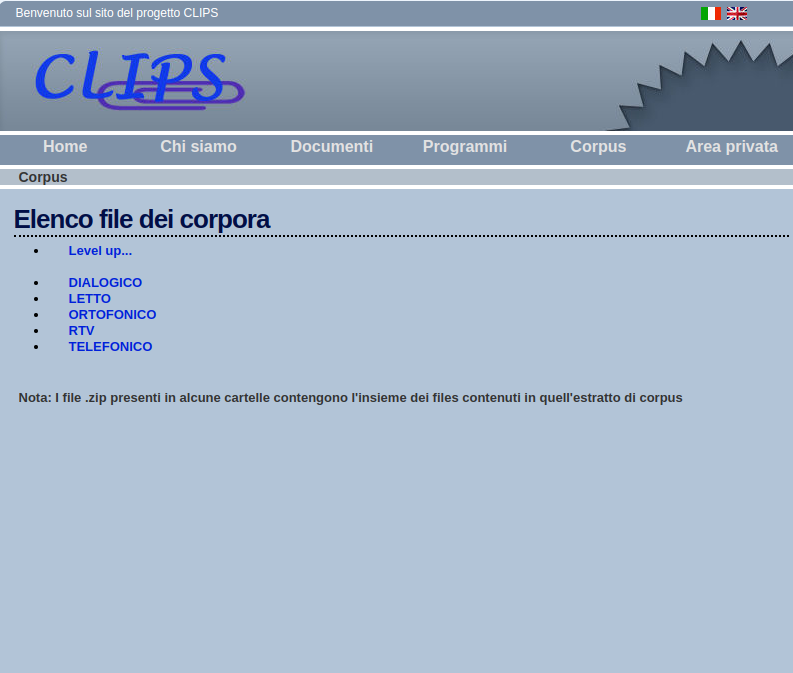
Ampio progetto coordinato dal prof. Federico Albano Leoni (CIRASS - Napoli) cui hanno partecipato l' Univ. "Federico II" di Napoli, la Scuola Normale Sup. di Pisa, la Fondazione Bordoni di Roma, e l' Ist. Sup. Poste e Telecomunicazioni, ora ISCOM. Autori ne sono i proff. F. A. Leoni, F. Cutugno e R Savy. Pubblicato nel 2006, contiene circa 100 ore di italiano parlato di varie tipologie suddiviso in 5 sottocorpora (radiotelevisivo, dialogico, letto, ortofonico, telefonico). Attraverso un'indagine sociolinguistica preliminare sul territorio italiano, sono state selezionate 15 città dove sono stati raccolti i materiali per la costituzione del corpus.
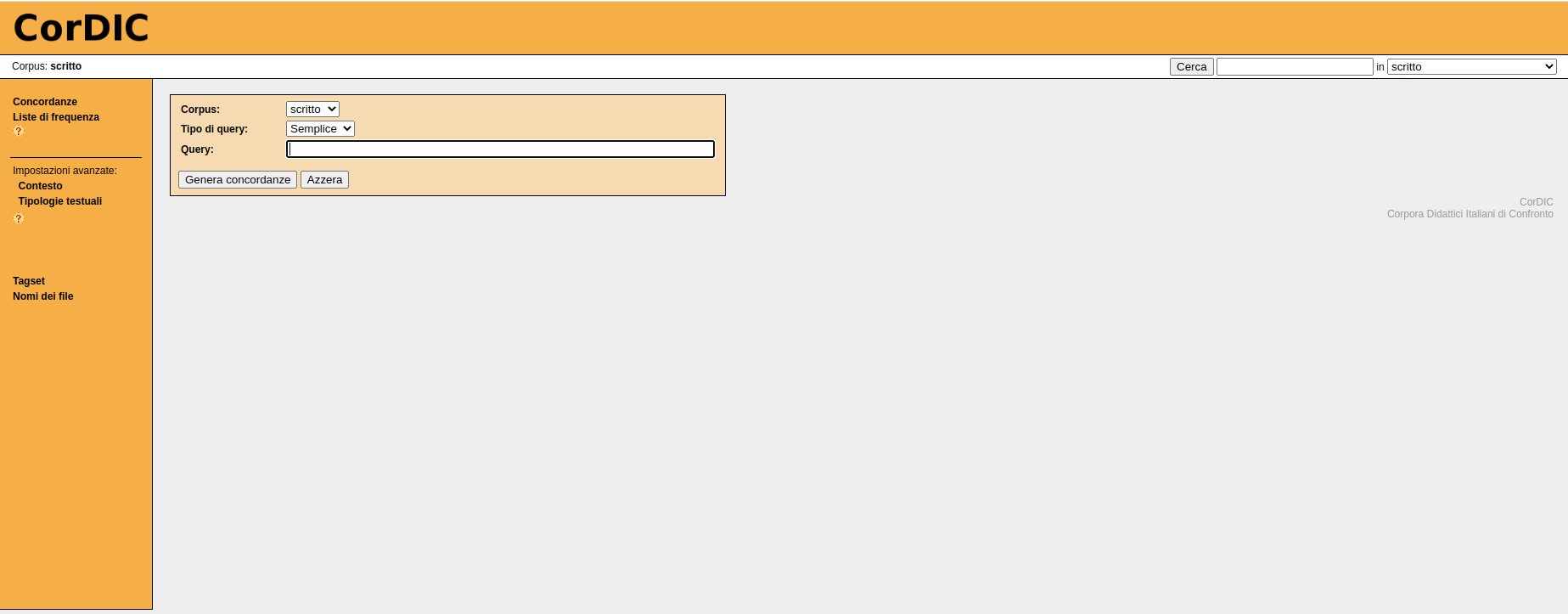
LABLITA (Laboratorio Linguistico Italiano dell'Università di Firenze) Corpora di italiano scritto e parlato da confrontare a scopo didattico; contiene circa un milione di parole divise tra testi e parlato spontaneo. È liberamente consultabile online.
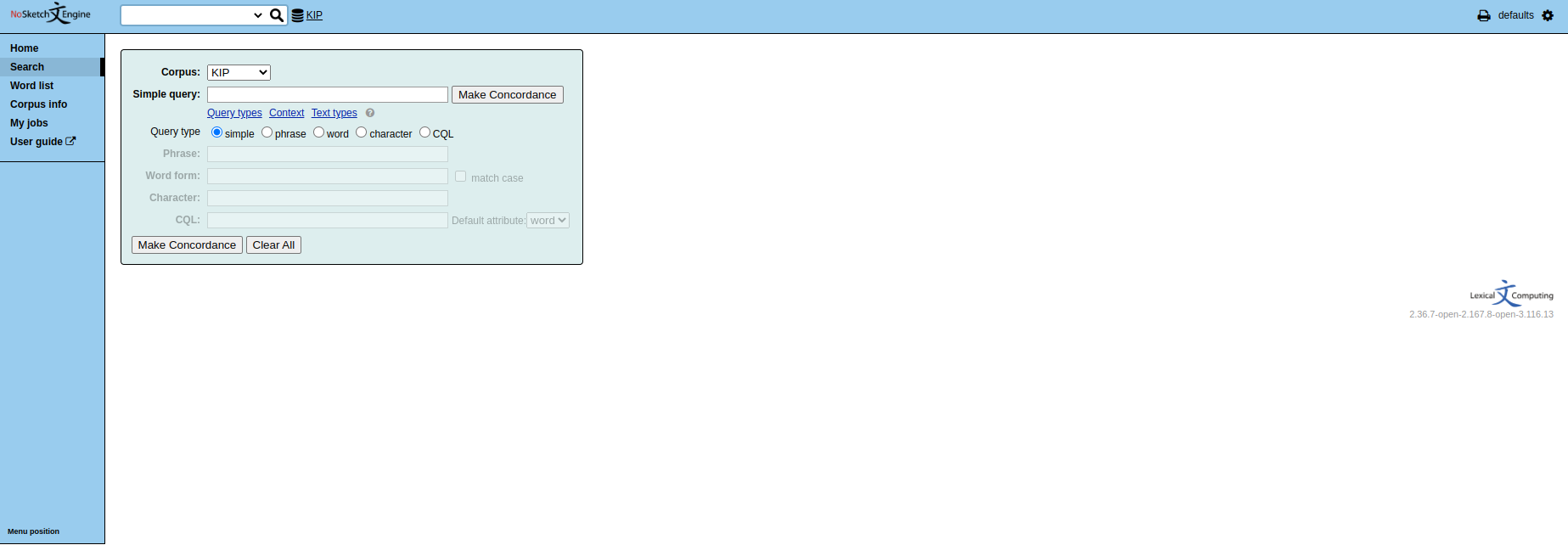
Caterina Mauri (Università di Bologna), Eugenio Goria, Silvia Ballarè e Massimo Cerruti (Università di Torino) Corpus di parlato registrato a Bologna e a Torino; comprende vari tipi d'interazione verbale fra parlanti con differente profilo sociolinguistico. I materiali sono consultabili in formato audio e in forma di trascrizione testuale allineata.

Accademia della Crusca Motore di ricerca che consente di interrogare contemporaneamente le tre banche dati (LessicoItalianoScritto, LessicoItalianoRadiofonico, LessicoItalianoTelevisivo) dell'Accademia della Crusca, per ottenere risultati di spettro più ampio e completo sulla lingua italiana contemporanea.

Corpus lemmatizzato, a cura dell'Opera del Vocabolario Italiano, del carteggio di Francesco Datini (1335-1410) composto da quasi 150.000 lettere e completo di commento in cui sono inseriti rimandi alle note editoriali.
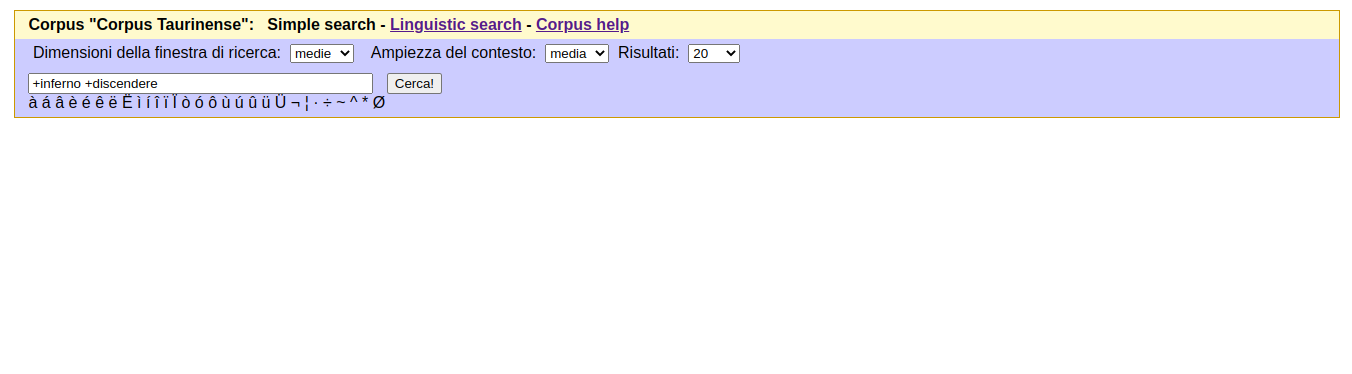
Raccolta di testi fiorentini del XIII secolo, ordinata per lemmi, parti del discorso, genere letterario e forme filologiche. Direzione scientifica di Manuel Barbera e Carla Marello.
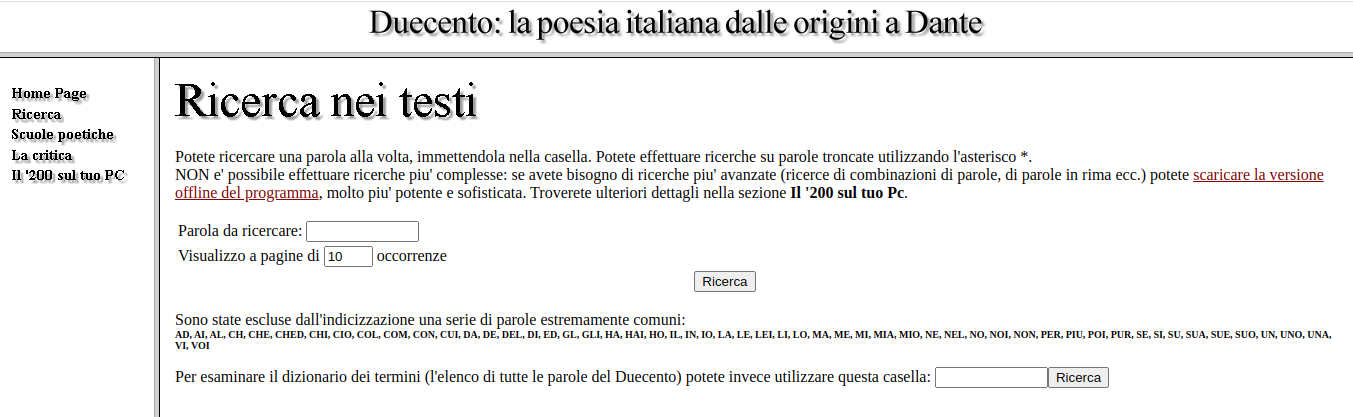
Archivio di testi digitalizzati della lirica italiana duecentesca curata dal 1993 da Andrea Bonomi. Il corpus è ricco di oltre 2.400 opere di oltre 200 autori tra maggiori e minori. È disponibile un motore di ricerca per la ricerca deli termini nei testi, con indice delle frequenze.
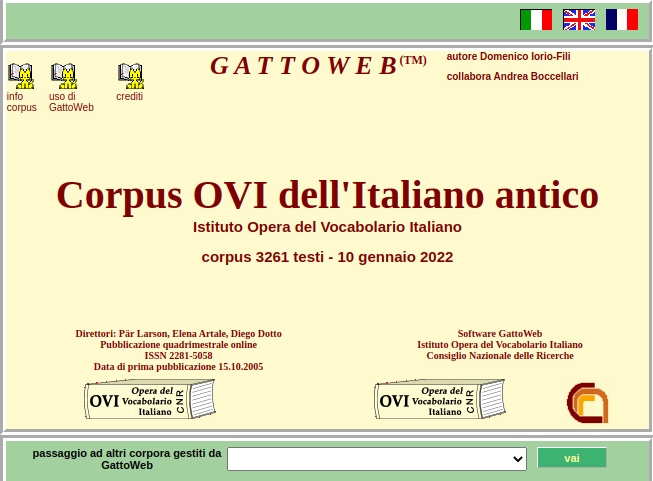
Raccolta completa dei testi italiani antichi resi accessibili dall'Opera del Vocabolario Italiano (OVI), ricca di 23 milioni di occorrenze per più di 450.000 forme grafiche distinte. Consente di scaricare brevi citazioni per uso di ricerca ma è vietato scaricare i testi. Direzione scientifica di Pär Larson, Elena Artale e Diego Dotto.
Corpus di Italiano Scritto contemporaneo ricco di circa 100 milioni di parole. Elaborato e prodotto dal Centro Interfacoltà di Linguistica Teorica e Applicata (CILTA) "Luigi Heilmann" dell'Universita' di Bologna, prevede una licenza per l'accesso alla versione completa.
Il corpus di riferimento è costituito da testi tratti da quotidiani del periodo 1992 - 1994 (La Repubblica, La Stampa, Il Corriere della Sera), periodici e libri, considerando anche i libri letti per motivi scolastici o professionali. Consta di 3.150.075 ricorrenze lessicali. Al progetto partecipano i seguenti soggetti: Scuola Normale Superiore (Pisa), Istituto di Scienze e Tecnologie della Cognizione del CNR (Roma), Università di Salerno, Istituto di Linguistica Computazionale, Unità Staccata di Genova del CNR, Università de L'Aquila.
Corpus molto ampio (circa 380mila parole) del lessico del quotidiano la Repubblica. Nel progetto, curato dall'Università di Bologna, il corpus è stato lemmatizzato, taggato e categorizzato per genere e topic; gli articoli nel corpus sono strutturati nelle seguenti parti:titolo, sottotitolo, sommario, testo.
Corpus lemmatizzato, a cura dell'Opera del Vocabolario Italiano, del carteggio di Francesco Datini (1335-1410) composto da quasi 150.000 lettere e completo di commento in cui sono inseriti rimandi alle note editoriali.
Raccolta di testi fiorentini del XIII secolo, ordinata per lemmi, parti del discorso, genere letterario e forme filologiche. Direzione scientifica di Manuel Barbera e Carla Marello.
Archivio di testi digitalizzati della lirica italiana duecentesca curata dal 1993 da Andrea Bonomi. Il corpus è ricco di oltre 2.400 opere di oltre 200 autori tra maggiori e minori. È disponibile un motore di ricerca per la ricerca deli termini nei testi, con indice delle frequenze.
Raccolta completa dei testi italiani antichi resi accessibili dall'Opera del Vocabolario Italiano (OVI), ricca di 23 milioni di occorrenze per più di 450.000 forme grafiche distinte. Consente di scaricare brevi citazioni per uso di ricerca ma è vietato scaricare i testi. Direzione scientifica di Pär Larson, Elena Artale e Diego Dotto.
il corpus LIP, ospitato sul sito della Banca Dati dell'Italiano Parlato (BaDIP), è la raccolta di testi dell'italiano parlato più importante e più utilizzata nella ricerca linguistica. Costituito nel 1990-1992 da un gruppo di linguisti diretto da Tullio De Mauro, serví per costruire il primo lessico di frequenza dell' italiano parlato. I suoi 469 testi, contenenti complessivamente ca. 490.000 parole, furono raccolti in quattro città (Milano, Firenze, Roma e Napoli) e provengono da cinque macroclassi e numerose sottoclassi di discorso.
Ampio progetto coordinato dal prof. Federico Albano Leoni (CIRASS - Napoli) cui hanno partecipato l' Univ. "Federico II" di Napoli, la Scuola Normale Sup. di Pisa, la Fondazione Bordoni di Roma, e l' Ist. Sup. Poste e Telecomunicazioni, ora ISCOM. Autori ne sono i proff. F. A. Leoni, F. Cutugno e R Savy. Pubblicato nel 2006, contiene circa 100 ore di italiano parlato di varie tipologie suddiviso in 5 sottocorpora (radiotelevisivo, dialogico, letto, ortofonico, telefonico). Attraverso un'indagine sociolinguistica preliminare sul territorio italiano, sono state selezionate 15 città dove sono stati raccolti i materiali per la costituzione del corpus.
Caterina Mauri (Università di Bologna), Eugenio Goria, Silvia Ballarè e Massimo Cerruti (Università di Torino) Corpus di parlato registrato a Bologna e a Torino; comprende vari tipi d'interazione verbale fra parlanti con differente profilo sociolinguistico. I materiali sono consultabili in formato audio e in forma di trascrizione testuale allineata.
LABLITA (Laboratorio Linguistico Italiano dell'Università di Firenze) Corpora di italiano scritto e parlato da confrontare a scopo didattico; contiene circa un milione di parole divise tra testi e parlato spontaneo. È liberamente consultabile online.
Accademia della Crusca Motore di ricerca che consente di interrogare contemporaneamente le tre banche dati (LessicoItalianoScritto, LessicoItalianoRadiofonico, LessicoItalianoTelevisivo) dell'Accademia della Crusca, per ottenere risultati di spettro più ampio e completo sulla lingua italiana contemporanea.
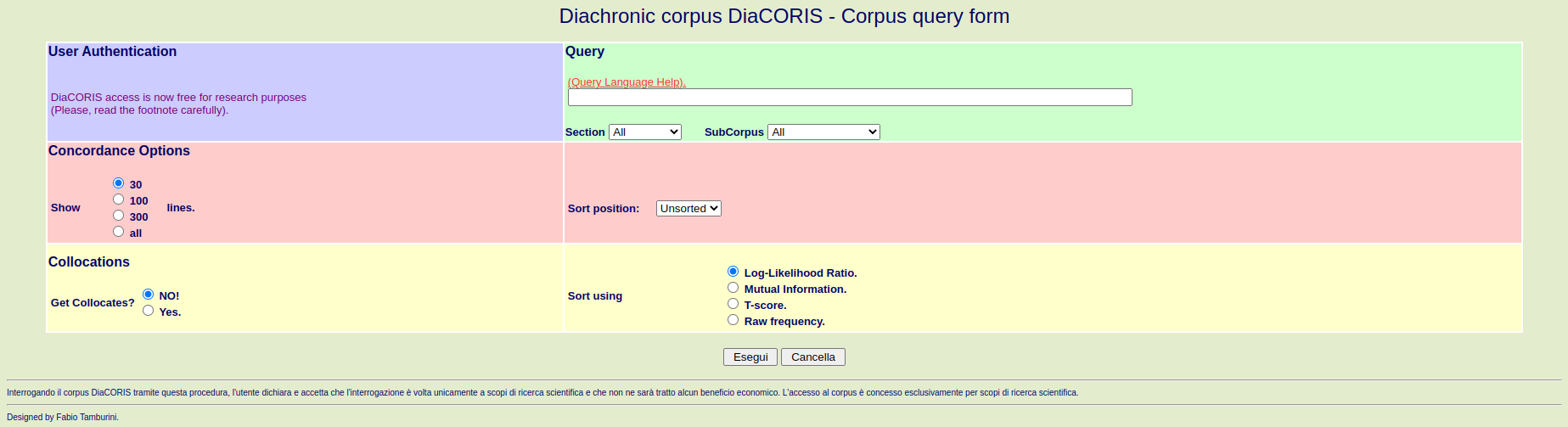
Rema Rossini Favretti, Alma Mater Studiorum - Università di Bologna Corpus diacronico dell'italiano scritto, comprendente testi prodotti tra il 1861 e il 2001. È liberamente consultabile online.